OpenClaw架构浅析

在大语言模型(LLM)快速普及的当下,AI Agent被视为大模型从“对话工具”走向“落地生产力”的核心载体。而台湾大学李宏毅(Hung-yi Lee)老师的AI Agent课程中,被戏称为“小龙虾”的OpenClaw,用一套极简又完整的架构,把复杂的AI Agent运作逻辑拆解的明明白白。它不仅是一个可落地的轻量化AI Agent实现,更是理解通用AI Agent运作原理的好途径
一、先搞懂:OpenClaw到底是什么?
要理解OpenClaw,首先要分清大语言模型(LLM)与AI Agent的核心边界。
传统的LLM,本质是一套“只动口不动手”的文字接龙智能——它能完成文本生成、逻辑推理、问答对话,但无法直接触达真实世界,不能执行文件操作、软件调用、流程自动化等落地动作,所有能力都局限在文本框内。
而OpenClaw为代表的AI Agent,核心就是给“只动口”的LLM装上了“能动的手脚”和“能记的大脑”。它是一套打通了云端LLM智能与本地执行能力的AI代理框架,核心架构分为双向联动的两部分:
- 云端LLM:是整个Agent的“灵魂与大脑”,负责决策、推理、规划,提供核心的智能能力;
- 本地Agent程序:是无原生智能的“躯体与钳子”,仅作为交互界面和执行载体,负责刚性执行LLM输出的指令,完成绘图、视频制作、文件读写、YouTube设置等真实世界的操作。
也正是这套“云端大脑+本地执行”的架构,让OpenClaw被爱好者们起了“小龙虾”的昵称——它像小龙虾一样,用大脑指挥钳子,完成各类落地动作,把LLM的文本智能,转化成了真实的生产力。
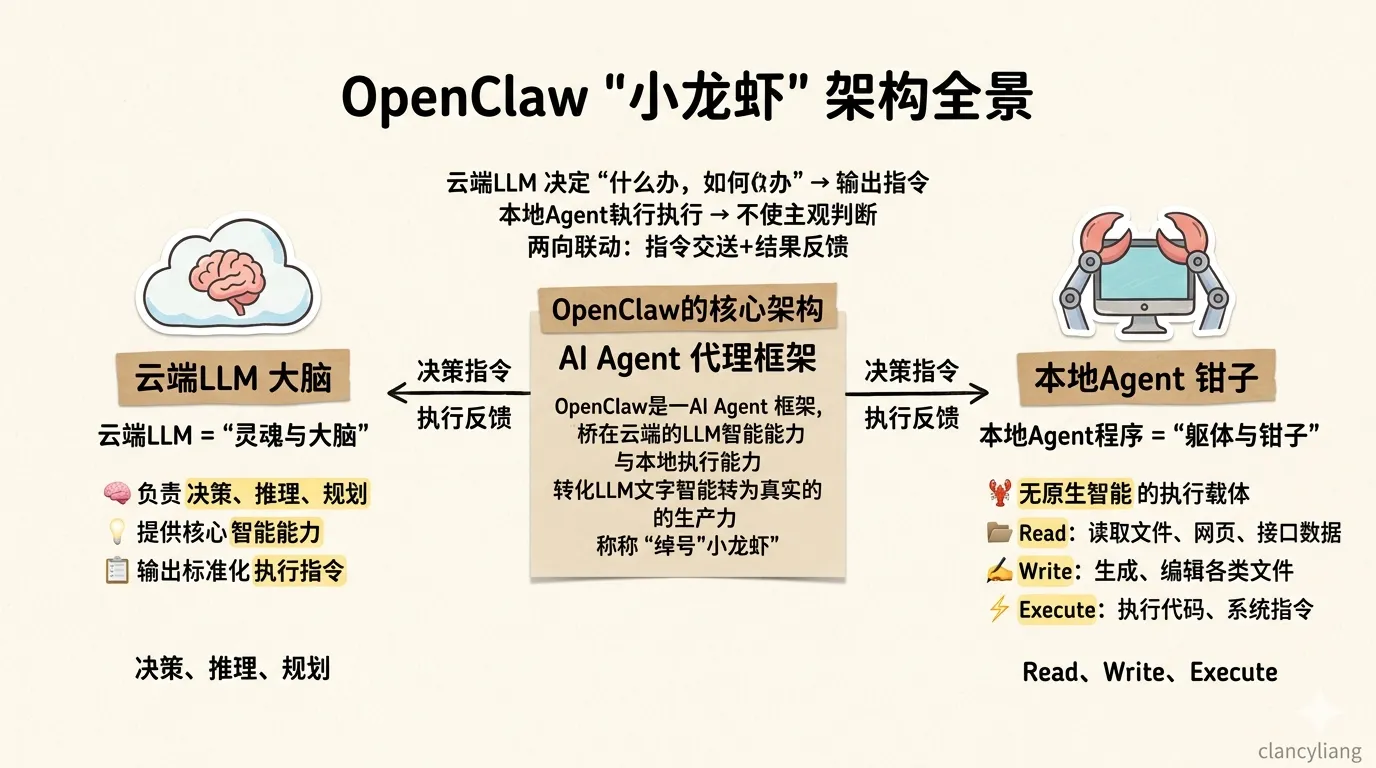
二、OpenClaw的核心运作闭环:从用户请求到自主执行的全流程
OpenClaw的运作,本质是一套“身份锚定-需求拆解-工具执行-上下文管理-长期对齐-安全兜底”的完整闭环,每一个环节都精准解决了LLM的原生短板,最终实现AI Agent的稳定运行。
2.1 第一步:身份锚定与记忆唤醒——解决LLM的天生“失忆症”
大语言模型有一个原生缺陷:天生的“失忆症”。它无法自主留存长期记忆,也无法在多轮对话中始终保持稳定的身份认知,很容易出现人设跑偏、忘记前文需求的问题。这也是OpenClaw运作的第一个核心环节:先定住“我是谁”,再想“我要做什么”。
当用户发起请求时,OpenClaw不会直接把问题丢给LLM,而是先完成一轮预处理:
- 加载本地固化的身份配置文件(如soul.md、agents.behavior)和System Prompt(系统提示词),给LLM锚定固定的身份、行为准则、能力边界,避免对话中出现人设崩塌;
- 调取对话历史记录(记忆重连卡),还原之前的对话语境和任务进度,让LLM能连贯承接需求,而不是每次都从零开始;
- 完成身份与记忆的整合后,再把预处理后的有效内容输入给LLM,同时避免了全量对话历史直接输入带来的高Token消耗问题。
2.2 第二步:需求拆解与工具执行——给LLM装上“可动手的钳子”
这是OpenClaw区别于普通LLM的核心环节,也是AI Agent“能动口也动手”的关键。
当LLM明确了身份与需求后,会按照System Prompt设定的规则,对用户需求进行拆解,匹配对应的执行工具与标准化流程(SOP)。OpenClaw的核心执行工具分为三类,覆盖了绝大多数落地场景:
- Read:读取本地文件、网页数据、外部接口信息,为决策提供数据支撑;
- Write:生成、编辑、写入各类文件,包括文案、脚本、代码、表格等内容;
- Execute:执行代码、系统指令、软件操作,完成自动化流程的落地。
整个执行逻辑非常清晰:LLM只负责决策“做什么、怎么做”,输出标准化的执行代码与指令;本地的OpenClaw程序负责刚性执行,完全按照指令操作,不做任何主观判断。
也正是这套执行逻辑,带来了Agent的核心风险:Execute指令可执行任意系统指令,一旦出现提示词注入攻击、LLM幻觉输出高危指令(如系统文件删除指令),就可能引发严重的安全事故。这也是OpenClaw在设计中,始终把安全防御作为核心环节的原因。
2.3 第三步:上下文动态管理——突破Token上限的长期运行基础
大模型的上下文窗口(Context Window)有固定的Token上限,而AI Agent的长期运行,会产生海量的对话历史、执行日志、知识库内容,很容易就超出Token上限,导致程序报错、LLM无法正常响应。
OpenClaw通过一套完整的上下文工程(Token管理),用三种核心方案解决了这个问题,实现了上下文的高效缩用:
- RAG知识检索(Local Memory):把海量的知识库、历史记忆存入本地的Memory.md文件,拆分成多个独立的文本块(Chunks),通过向量化Embedding或关键词匹配实现语义召回。每次只给LLM加载和当前需求相关的内容,避免全量知识库占用Token额度;
- Skill(技能/SOP)固化:把视频制作、图文生成这类固定的工作流,做成标准化的SOP存入本地.md文件,采用“按需加载”的模式,只有当需要用到对应技能时,才把流程提示词输入给LLM,实现固定技能的永久Token复用;
- 上下文压缩与修剪:对多轮对话历史进行摘要压缩,把多轮对话浓缩成核心信息,减少无效Token占用;对长期执行过程中产生的冗余日志、中间输出进行裁剪,分为保留核心信息的软裁剪(Soft Trim)和直接删除无效内容的硬切除(Hard Clear),进一步优化Token使用效率。
2.4 第四步:心跳与排程机制——实现真正的“自主长期运作”
普通的LLM对话是“单次触发、单次响应”,而AI Agent的核心价值,是能实现无人值守的长期自主运作。OpenClaw通过两套核心机制,实现了这个能力:
- 心跳机制(Heartbeat):每隔固定时长,OpenClaw就会主动给LLM发送固定的对齐指令,比如检查Habit.md中的长期目标,核对当前任务进度,确保Agent在长期运行中不会偏离预设的核心目标,避免出现“跑歪”的情况;
- Cronjob排程系统:给AI赋予了“等待”能力,可实现对外部AI工具、第三方服务的全流程控制。比如Agent可以注册一个绘图任务,等待绘图工具完成出图后,自动触发后续的视频合成、配音等流程,无需人工干预,实现复杂任务的全自动化排程与执行。
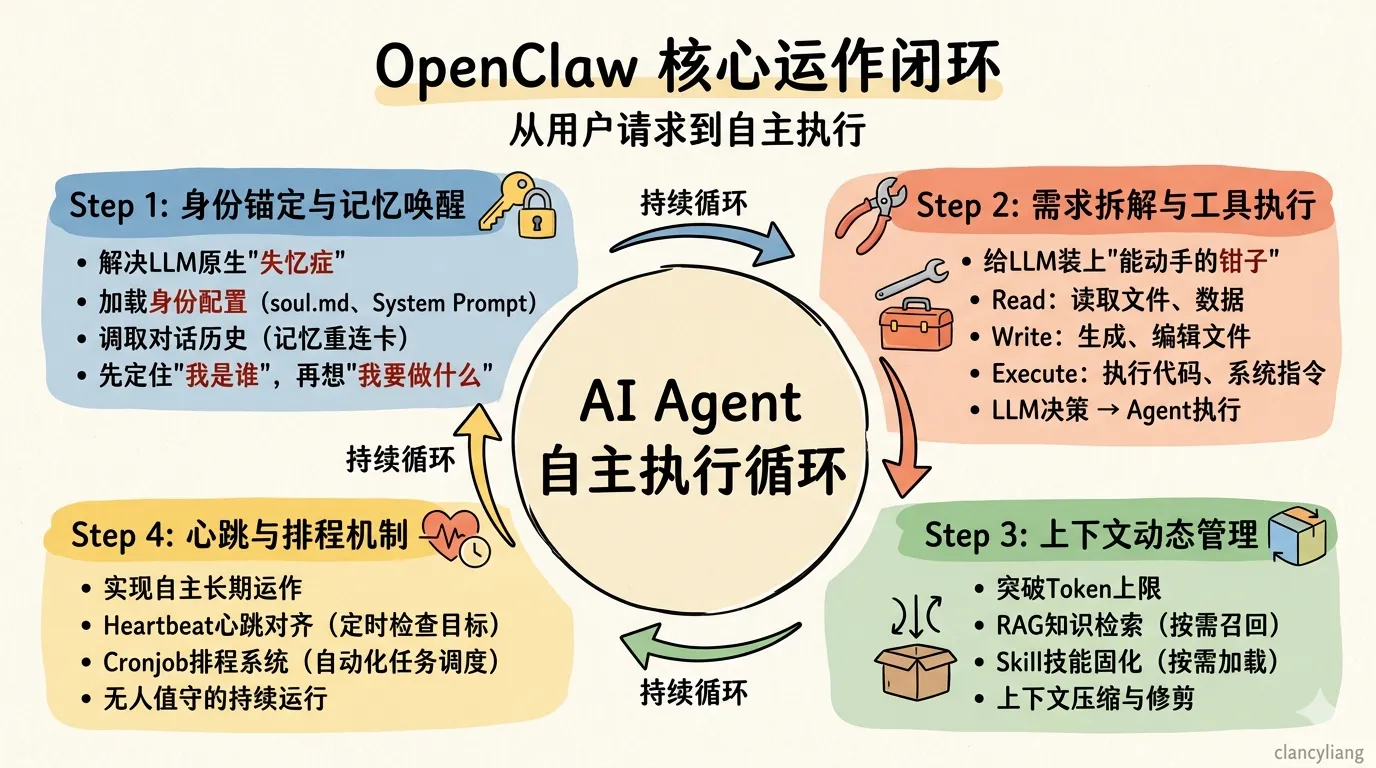
三、安全兜底:OpenClaw的防“搞事”核心设计
AI Agent落地的核心前提,是先解决“AI搞事”的风险,再谈“AI做事”的价值。OpenClaw的整套设计中,安全是贯穿始终的核心准则,核心理念只有四个字:隔离是关键。
其核心的安全设计分为四个维度:
- 严格的沙盒隔离:用独立的专属设备、独立的账号体系运行Agent,和用户日常使用的设备、个人账号完全拆分,哪怕Agent出现高危操作,也不会影响用户的核心数据与日常使用;
- 全流程监督审计:不仅关注Agent的最终执行结果,更要检查完整的执行过程,设置专门的审校沙盒环节,对每一步执行指令进行校验,避免幻觉指令带来的风险;
- 安全规则的永久固化:核心安全准则必须写入永久记忆文件memory.md、System Prompt中,绝对不能只写在历史对话里。课程中“误删邮件事件”的核心教训就是:仅存于历史对话的规则,会随着上下文修剪被删除,最终导致安全规则失效;
- 人工审核兜底:对高危的Execute执行指令,设置人工审核环节,确认指令无风险后再放行执行,从源头杜绝提示词注入、幻觉高危操作的风险。
四、总结
OpenClaw的运作原理,本质上也是当下绝大多数通用AI Agent的核心逻辑:以大语言模型为决策大脑,通过身份与记忆管理解决LLM的失忆问题,通过工具调用赋予LLM落地执行的能力,通过上下文工程突破Token的物理限制,通过心跳与排程实现长期自主运作,最终用一套完整的安全体系,给Agent的运行装上“刹车”。