如何使用MCP构建更高效的Code Agent
模型上下文协议(MCP) 是一套用来把 AI 智能体和外部系统”对接”起来的开放标准。以往要让智能体连上某个工具或数据源,往往得为每一对组合单独做定制开发——这不仅造成系统碎片化,还产生大量重复劳动,想做到真正可扩展的互联系统非常困难。MCP 提供了一个统一协议:开发者只需在自己的智能体里接入一次 MCP,就能解锁整个集成生态。
自 2024 年 11 月发布以来,MCP 的发展势头堪称迅猛:社区已经搭起了数千个 MCP 服务器,各主流编程语言也都有了配套 SDK,业界更是默认把 MCP 当成了连接智能体与工具、数据的”事实标准”。
如今,开发者们日常构建的 AI 智能体,动辄就能访问分布在几十个 MCP 服务器上的成百上千个工具。然而,随着连接工具的数量不断增长,“在智能体运行之初就加载所有工具的定义” 以及 “让所有中间结果都通过上下文窗口” 的做法,会拖慢智能体的速度并推高成本。
你可以把"上下文"想象成智能体面前的一张"临时工作台":当前问题、历史对话、工具使用说明和刚拿到的数据都要先摊在这张台子上,它才能继续推理。它有三个典型特点:第一,空间有限(放太多会挤爆,重要信息可能被截断);第二,内容会滚动(新信息不断进入,旧信息可能被挤出);第三,越长越贵(读得越多,延迟和 token 成本越高)。本文要探讨的,就是如何通过代码执行,让智能体与 MCP 服务器交互时更高效——用更少的token,搞定更多的工具。
工具过度消耗token,会让智能体变低效
随着 MCP 的使用规模扩大,有两种常见模式会增加智能体的成本和延迟:
- 工具定义把上下文窗口挤爆;
- 工具中间结果会消耗额外token
1. 工具定义把上下文窗口挤爆
多数 MCP 客户端会在一开始就把全部工具定义直接加载进上下文,并通过直接工具调用语法暴露给模型。这些工具定义可能像这样:
gdrive.getDocument
Description: Retrieves a document from Google Drive
Parameters:
documentId (required, string): The ID of the document to retrieve
fields (optional, string): Specific fields to return
Returns: Document object with title, body content, metadata, permissions, etc.salesforce.updateRecord
Description: Updates a record in Salesforce
Parameters:
objectType (required, string): Type of Salesforce object (Lead, Contact, Account, etc.)
recordId (required, string): The ID of the record to update
data (required, object): Fields to update with their new values
Returns: Updated record object with confirmation这些工具描述占用了宝贵的上下文窗口空间,增加了响应时间和成本。想象一下,当一个智能体连接了数千个工具时,它可能在”读到用户的请求之前”,就必须先处理掉几十万 token 的工具定义。
2. 工具中间结果会消耗额外token
多数 MCP 客户端允许模型直接调用 MCP 工具。举个例子,你让智能体做一件事:“帮我把 Google Drive 上的会议纪要下载下来,然后附加到 Salesforce 的潜在客户记录里。”
模型会像下面这样执行工具调用:
TOOL CALL: gdrive.getDocument(documentId: "abc123")
→ returns "Discussed Q4 goals...\n[full transcript text]"
(loaded into model context)
TOOL CALL: salesforce.updateRecord(
objectType: "SalesMeeting",
recordId: "00Q5f000001abcXYZ",
data: { "Notes": "Discussed Q4 goals...\n[full transcript text written out]" }
)
(model needs to write entire transcript into context again)每一个中间结果都必须“过一遍”模型。在这个例子里,完整的会议纪要内容被“来来回回”处理了两次。如果这是一场 2 小时的销售会议,可能就意味着额外处理了 50,000 个 Token。如果文档再大一点,甚至可能直接撑爆上下文窗口的限制,导致整个工作流中断。
而且,面对大文档或复杂数据结构,模型在工具调用之间“复制粘贴”数据时也更容易出错。
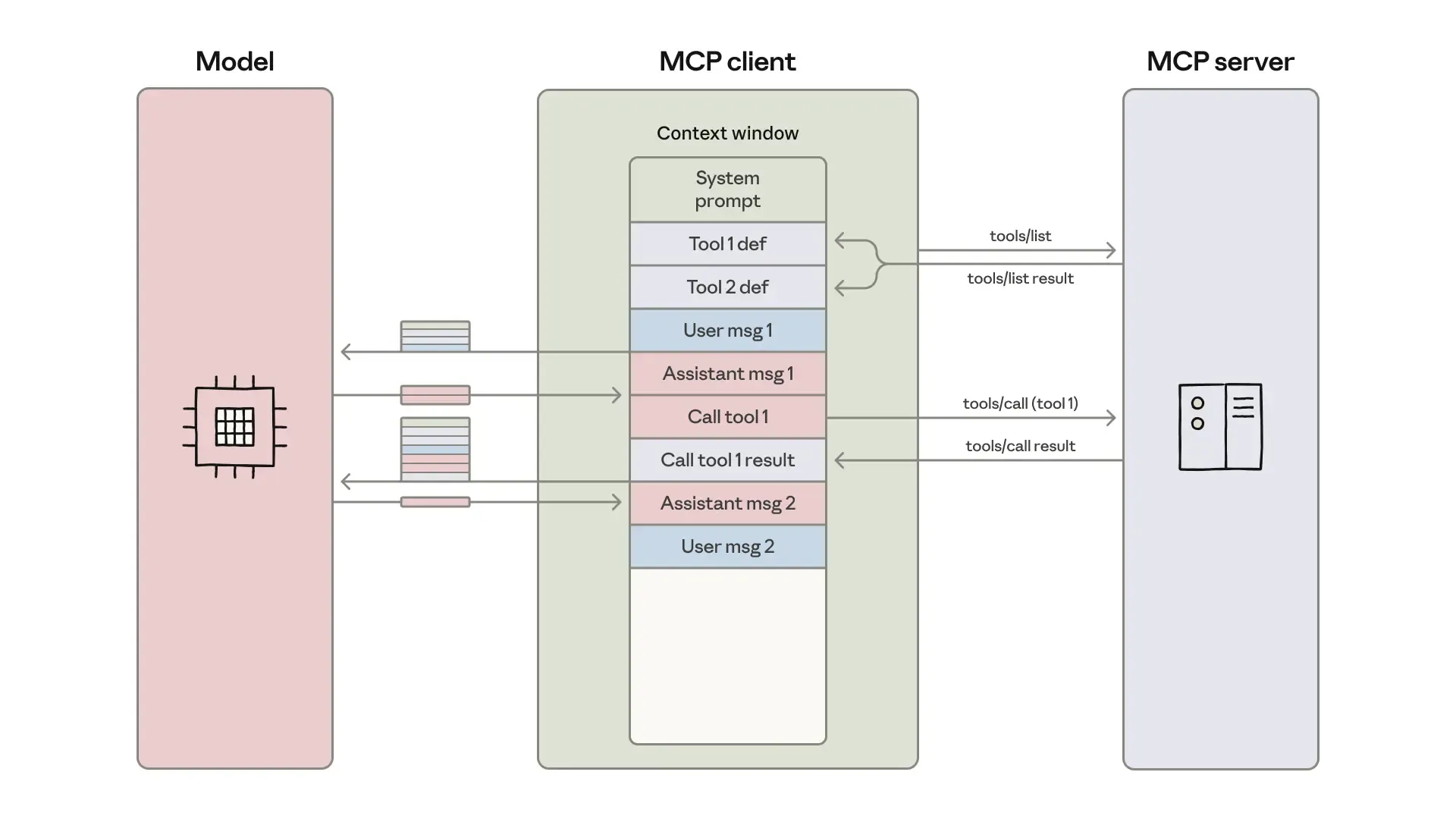
MCP 客户端把工具定义加载到模型的上下文窗口中,然后编排一个消息循环——每一次工具调用和返回结果,都要在操作之间通过模型传递。
把MCP当代码来执行更省上下文
既然代码执行环境在智能体中越来越普及,一个很自然的思路就是:别再把 MCP 服务器暴露成”直接工具调用”了,而是把它们包装成代码 API,让智能体写代码来调用。这种方法同时解决了前面提到的两个问题:智能体可以只加载需要的工具,并且在执行环境中把数据处理”干净“后再传回给模型。
具体怎么做呢?有很多种实现方式。其中一种,是把所有连接上的 MCP 服务器的可用工具,生成一个文件树。下面是一个 TypeScript 的例子:
servers
├── google-drive
│ ├── getDocument.ts
│ ├── ... (other tools)
│ └── index.ts
├── salesforce
│ ├── updateRecord.ts
│ ├── ... (other tools)
│ └── index.ts
└── ... (other servers)每个工具对应一个文件,大概长这样:
// ./servers/google-drive/getDocument.ts
import { callMCPTool } from "../../../client.js";
interface GetDocumentInput {
documentId: string;
}
interface GetDocumentResponse {
content: string;
}
/* Read a document from Google Drive */
export async function getDocument(input: GetDocumentInput): Promise<GetDocumentResponse> {
return callMCPTool<GetDocumentResponse>('google_drive__get_document', input);
}前面那个”Google Drive → Salesforce”的例子,用代码来写就变成了:
// Read transcript from Google Docs and add to Salesforce prospect
import * as gdrive from './servers/google-drive';
import * as salesforce from './servers/salesforce';
const transcript = (await gdrive.getDocument({ documentId: 'abc123' })).content;
await salesforce.updateRecord({
objectType: 'SalesMeeting',
recordId: '00Q5f000001abcXYZ',
data: { Notes: transcript }
});智能体发现工具的方式也很优雅:先浏览 ./servers/ 目录,看看有哪些可用的服务器(比如 google-drive 和 salesforce),然后只读取当前任务需要的那几个工具文件(比如 getDocument.ts、updateRecord.ts)来了解接口定义。这样一来,它只加载真正用得上的定义。token 消耗从 150,000 降到了 2,000——时间和成本节省了 98.7%。
Cloudflare 也发布了类似研究成果,他们管这种模式叫”Code Mode”。其核心洞察是一致的:大语言模型擅长编写代码,开发者应利用这一优势构建能更高效地与MCP服务器交互的智能体。
代码执行 + MCP 的优势
MCP结合代码执行,智能体可以按需加载工具、在数据到达模型之前先过滤、一步到位执行复杂逻辑——让上下文的使用更高效。此外,这种方式在安全性和状态管理上也有好处。
渐进式披露(Progressive Disclosure)
模型很擅长遍历文件系统。把工具以代码文件的形式呈现在文件系统上,模型就能按需读取工具定义,而不是在一开始就把所有定义全部读进来。
还有一种做法是在服务器上加一个 search_tools (搜索工具)的工具,专门用来查找相关定义。比如用前面假设的 Salesforce 服务器举例:智能体搜索 “salesforce”,然后只加载当前任务需要的那几个工具。如果 search_tools 还支持更新粒度的参数——比如”仅名称”、“名称+描述”、“包含schemas的完整定义”——就能进一步帮智能体节省上下文、快速找到目标工具。
更省上下文:在代码里先处理好数据
面对大数据集时,智能体可以先在代码里完成筛选和转换,再把精炼后的结果交给模型。假设要读取一个 10,000 行的电子表格:
// 不用代码执行 — 10,000 行全部灌进上下文
TOOL CALL: gdrive.getSheet(sheetId: 'abc123')
→ 在上下文中返回 10,000 行数据,等待模型手动筛选
// 用代码执行 — 在执行环境里先筛选
const allRows = await gdrive.getSheet({ sheetId: 'abc123' });
const pendingOrders = allRows.filter(row =>
row["Status"] === 'pending'
);
console.log(`Found ${pendingOrders.length} pending orders`);
console.log(pendingOrders.slice(0, 5)); // 只打印前 5 个供模型审阅最终,智能体(模型)只看到了 5 行数据,而不是 10,000 行。类似的模式也适用于数据聚合、跨多个数据源的连接,或者提取特定字段——所有这些操作都不会撑爆上下文窗口。
循环、条件判断和错误处理,现在都可以用我们熟悉的编程模式来完成,而不是靠一长串独立的工具调用链。例如,如果你需要一个 Slack 部署通知,智能体可以这样写:
let found = false;
while (!found) {
const messages = await slack.getChannelHistory({ channel: 'C123456' });
found = messages.some(m => m.text.includes('deployment complete'));
if (!found) await new Promise(r => setTimeout(r, 5000));
}
console.log('已收到部署通知');这比让智能体在循环里反复”调工具→休眠等待→再调工具”高效得多。
不仅如此,把整棵条件分支树写成可执行代码,还能降低”首 token 延迟”(time to first token):不用等模型逐步评估 if 语句,直接让代码执行环境来处理就好。
保护隐私的操作方式
当智能体通过 MCP 使用代码执行时,所有中间结果默认都只留在执行环境里。智能体只能看到你显式 打印 或 返回 的内容,那些你不想暴露给模型的数据,可以在工作流中正常流转,而根本无需进入模型的上下文。
对于更敏感的场景,智能体框架还可以自动对敏感数据做脱敏(tokenization)。比如你要把一张电子表格里的客户联系方式批量导入 Salesforce,智能体会写出这样的代码:
const sheet = await gdrive.getSheet({ sheetId: 'abc123' });
for (const row of sheet.rows) {
await salesforce.updateRecord({
objectType: 'Lead',
recordId: row.salesforceId,
data: {
Email: row.email,
Phone: row.phone,
Name: row.name
}
});
}
console.log(`已更新 ${sheet.rows.length} 条潜在客户信息`);MCP 客户端会在数据送达模型之前拦截下来,把个人身份信息(PII)脱敏处理,替换成占位符:
// 如果智能体打印了 sheet.rows,它会看到这样的内容:
[
{ salesforceId: '00Q...', email: '[EMAIL_1]', phone: '[PHONE_1]', name: '[NAME_1]' },
{ salesforceId: '00Q...', email: '[EMAIL_2]', phone: '[PHONE_2]', name: '[NAME_2]' },
...
]等到数据需要在下一次 MCP 工具调用中使用时,MCP 客户端再通过查表把占位符还原成真实值。这样一来,真实的邮箱、电话和姓名从 Google Sheets 流向 Salesforce,但不会经过模型。这能防止智能体(指其中的大模型)意外记录或处理敏感数据。你也可以借此定义确定性的安全规则,控制数据可以流向哪里、从哪里获取。
状态持久化与“技能”复用
代码执行加上文件系统访问,让智能体拥有了跨操作”记住东西”的能力。它可以把中间结果写到文件里,下次接着干、随时看进度:
const leads = await salesforce.query({
query: 'SELECT Id, Email FROM Lead LIMIT 1000'
});
const csvData = leads.map(l => `${l.Id},${l.Email}`).join('\n');
await fs.writeFile('./workspace/leads.csv', csvData);
// 之后的执行可以从它上次中断的地方继续
const saved = await fs.readFile('./workspace/leads.csv', 'utf-8');更妙的是,智能体还能把自己写过的代码沉淀成可复用的函数。某个任务的代码跑通了?保存下来,以后直接调用就行:
// 保存在 ./skills/save-sheet-as-csv.ts
import * as gdrive from './servers/google-drive';
export async function saveSheetAsCsv(sheetId: string) {
const data = await gdrive.getSheet({ sheetId });
const csv = data.map(row => row.join(',')).join('\n');
await fs.writeFile(`./workspace/sheet-${sheetId}.csv`, csv);
return `./workspace/sheet-${sheetId}.csv`;
}
// 之后,在任何一次智能体执行中:
import { saveSheetAsCsv } from './skills/save-sheet-as-csv';
const csvPath = await saveSheetAsCsv('abc123');这就和 Skills(技能) 的概念完美呼应了:Skills 说白了就是多个包含可复用的指令、脚本和资源的文件夹,帮模型在特定任务上做得更好。给这些保存下来的函数加上一个 SKILL.md 文件,就形成了结构化的技能,供模型随时检索和调用。日积月累,你的智能体会构建起一个越来越强大的能力工具箱,不断进化出它高效工作所需的“脚手架”
需要注意的是,代码执行本身也会带来额外的复杂性。运行智能体生成的代码,你得有一套安全的执行环境,配上合适的沙箱机制、资源限制和监控手段。这些基础设施需求会增加运维负担和安全考量,而直接工具调用在这方面则简单得多。所以是否采用代码执行,需要在它的收益(更低的 token 成本、更低的延迟、更强的工具组合能力)和这些实现成本之间做权衡。
总结
MCP 为智能体连接各种工具和系统提供了基础协议。但当连接的服务器太多时,工具定义和返回结果会消耗过多 token,降低智能体的效率。
虽然这里面的很多问题看起来很新——比如上下文管理、工具组合、状态持久化——但它们在软件工程领域其实都有成熟的解决方案。代码执行做的事情,就是把这些已有的编程模式应用到智能体身上,让它们用熟悉的编程方式更高效地与 MCP 服务器交互。如果你也实践了这种方法,我们鼓励你把经验分享给 MCP 社区。